
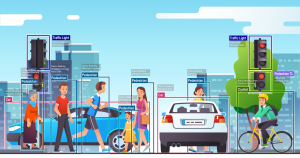
Pencitraan komputer menggabungkan kamera, komputasi tepi, komputasi berbasis cloud, perangkat lunak, dan Artificial Intelligence (AI) untuk membantu sistem “melihat” dan mengidentifikasi objek. Intel memiliki portofolio teknologi penerapan AI yang lengkap, termasuk CPU untuk tujuan umum, Computer Vision, dan unit visi (VPU) untuk akselerasi. Sistem Computer Vision yang bermanfaat di berbagai lingkungan dapat mengeali objek dan orang dengan cepat, menganalisis demografi khalayak, memeriksa hasil produksi, juga banyak hal lainnya.
Computer Vision menggunakan pembelajaran mendalam untuk membentuk jaringan saraf yang memandu sistem dalam mencoba dan menganalisis Teknik Jaringan Saraf Convolutional (CNN), dipisahkan sesuai dengan desain toolkit Intel® Distribution of OpenVINO™, mengingatkan pada pembelajaran mendalam untuk pembelajaran klasik dan deteksi objek . Model Computer Vision yang telah sepenuhnya berhasil dapat mengeali objek, mendeteksi dan mengeali orang, bahkan melacak pergerakan.
Sistem computer vision saat ini mendukung berbagai industri, mulai dari manufaktur, ritel, hingga keuangan, untuk membantu mengembangkan bisnis dan meningkatkan AI di edge. Deteksi objek, pengenalan objek, dan klasifikasi objek adalah fungsi utama dalam sistem computer vision saat ini.
Visi komputer membutuhkan banyak data. Ini menjalankan analisis data berulang-ulang sampai membedakan perbedaan dan akhirnya mengenali gambar. Misalnya, untuk melatih komputer mengenali ban mobil, komputer perlu diberi banyak gambar ban dan item terkait ban untuk mempelajari perbedaan dan mengenali ban, terutama ban tanpa cacat.
Dua teknologi penting digunakan untuk mencapai ini: jenis pembelajaran mesin yang disebut pembelajaran mendalam dan jaringan saraf convolutional (CNN).
Pembelajaran mesin menggunakan model algoritmik yang memungkinkan komputer belajar sendiri tentang konteks data visual. Jika cukup data dimasukkan melalui model, komputer akan “melihat” data dan belajar sendiri untuk membedakan satu gambar dari yang lain. Algoritma memungkinkan mesin untuk belajar dengan sendirinya, daripada seseorang memprogramnya untuk mengenali gambar.
CNN membantu model pembelajaran mesin atau pembelajaran mendalam “melihat” dengan memecah gambar menjadi piksel yang diberi tag atau label. Ia menggunakan label untuk melakukan konvolusi (operasi matematika pada dua fungsi untuk menghasilkan fungsi ketiga) dan membuat prediksi tentang apa yang “dilihat”. Jaringan saraf menjalankan konvolusi dan memeriksa keakuratan prediksinya dalam serangkaian iterasi hingga prediksi mulai menjadi kenyataan. Ia kemudian mengenali atau melihat gambar dengan cara yang mirip dengan manusia.
Sama seperti manusia yang membuat gambar di kejauhan, CNN pertama-tama membedakan tepi keras dan bentuk sederhana, kemudian mengisi informasi saat menjalankan iterasi prediksinya. CNN digunakan untuk memahami gambar tunggal. Jaringan saraf berulang (RNN) digunakan dengan cara yang sama untuk aplikasi video untuk membantu komputer memahami bagaimana gambar dalam serangkaian bingkai terkait satu sama lain.