
Klasifikasi Dokumen Karya Ilmiah dengan Support Vector Machine: Transformasi Pengelolaan Informasi
– oemahwebsite Dalam era digital yang berkembang pesat, pengelolaan informasi menjadi tantangan yang semakin kompleks. Khususnya di dunia akademis, klasifikasi dokumen karya ilmiah memiliki peran penting dalam mempermudah akses dan penemuan informasi. Salah satu metode yang efektif untuk melakukan klasifikasi tersebut adalah menggunakan algoritma Support Vector Machine (SVM).
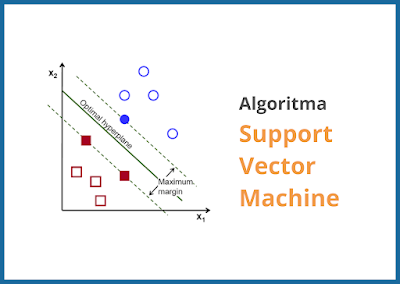
Support Vector Machine (SVM) dalam Klasifikasi Dokumen
SVM adalah algoritma pembelajaran mesin yang digunakan untuk klasifikasi dan regresi. Dalam konteks klasifikasi dokumen karya ilmiah, SVM bekerja dengan memetakan dokumen ke dalam ruang berdimensi tinggi dan mencari batas keputusan optimal yang memisahkan kategori dokumen yang berbeda. Kemampuannya dalam menangani data dengan dimensi tinggi membuat SVM menjadi pilihan yang efisien untuk tugas klasifikasi dokumen yang kompleks.
Langkah-langkah Klasifikasi Dokumen Menggunakan SVM
1. Pengumpulan Data: Langkah pertama adalah pengumpulan dataset dokumen karya ilmiah yang sudah dilabeli. Dataset ini akan digunakan untuk melatih model SVM agar dapat mengenali pola dan karakteristik setiap kategori dokumen.
2. Preprocessing Data: Dokumen perlu diproses untuk menghilangkan data yang tidak relevan, melakukan tokenisasi, dan mengatasi masalah seperti stop words atau stemming. Proses ini membantu meningkatkan kualitas dan akurasi klasifikasi.
3. Feature Extraction: Dokumen kemudian diubah menjadi representasi numerik yang dapat dimengerti oleh SVM. Teknik-teknik seperti Term Frequency-Inverse Document Frequency (TF-IDF) dapat digunakan untuk mengidentifikasi kepentingan relatif dari kata-kata dalam dokumen.
4. Pelatihan Model SVM: Dataset yang sudah diproses digunakan untuk melatih model SVM. Model ini akan belajar untuk mengidentifikasi pola dan hubungan antara fitur-fitur yang diekstraksi dan label kategori dokumen.
5. Evaluasi dan Penyesuaian: Setelah melatih model, evaluasi dilakukan menggunakan dataset uji yang terpisah. Model dapat disesuaikan dan dioptimalkan untuk meningkatkan kinerjanya.
Manfaat Klasifikasi Dokumen dengan SVM
Penerapan SVM dalam klasifikasi dokumen karya ilmiah membawa berbagai manfaat. Pertama, penelusuran informasi menjadi lebih efisien, memungkinkan peneliti dan akademisi untuk dengan cepat menemukan dokumen yang relevan. Kedua, pengelolaan arsip dan literatur ilmiah menjadi lebih terstruktur dan mudah diakses.
Dengan terus berkembangnya teknologi, pemanfaatan SVM dalam klasifikasi dokumen karya ilmiah memberikan kontribusi positif dalam memajukan pengelolaan informasi di dunia akademis. Integrasi teknologi ini tidak hanya meningkatkan efisiensi, tetapi juga mendukung kemajuan penelitian dan pertukaran pengetahuan dalam masyarakat ilmiah.
Sumber : www.academia.com